해당 내용을 전문적으로 공부하기 위해서는 컨테이너와 GPU, 인프라, 머신러닝 등에 대해 각각 전반적인 지식이 필요하다. 따라서 블로그에서는 최대한 기초적인 지식만 있어도 누구나 읽을 수 있도록 서술해보았다. 그리고 스터디 자료를 그대로 인용한 부분이 많다는 점 참고바란다.
기본적으로 머신러닝, 딥러닝을 포함하는 AI 기술은 별도로 발전을 하고 있었으나 고성능 GPU가 대중화되기 전까지는 빅데이터 수준에 머물렀다. 초기에 인공지능이라고 하면 대표적인게 알파고인데, 알파고는 빅데이터를 기점으로 학습한 데이터를 바탕으로 최선의 결과를 내는데는 성공했다고 보인다.
그러다가 점점 자연어, 비전 등 다양한 학문으로 발전을 하던 중 ChatGPT의 등장으로 AI가 매우 급부상하게 되었다.
이와 반대로 컨테이너 기술은 별도로 대중화된 상태이나 AI 모델은 워낙 무겁기때문에 고성능 하드웨어와 함께 서버에서 돌리는게 일반적이였다. 그러나 점점 하드웨어가 고성능화되고 네트워크 또한 대규모 모델의 등장들로 네트워크 스펙을 순식간에 올리게 되면서 컨테이너 환경에 대한 needs도 같이 들어온 것으로 보인다.
needs는 다음과 같다.
- 환경 구성의 복잡성: CUDA, cuDNN 등 복잡한 드라이버 스택 설치 및 관리가 필요. 특히 버전 호환성 문제로 인해 특정 프레임워크(TensorFlow, PyTorch)가 특정 CUDA/cuDNN 버전만 지원하는 경우가 많았음.
- 재현성 부족: 동일한 실험 환경을 다른 시스템에서 재현하기 어려움. '내 컴퓨터에서는 잘 작동하는데요?.'와 같은 이야기를 많이 들을 수 있었음.
- 리소스 비효율성: 고가의 GPU 리소스가 특정 사용자나 프로젝트에 고정되어 활용도가 저하. (베어메탈 GPU 서버의 활용률은 30% 미만인 경우가 많았음)
- 확장성 제한: 대규모 분산 학습을 위한 인프라 확장이 어려웠음. 새로운 GPU 서버를 추가할 때마다 동일한 환경 구성 과정을 반복 필요.
즉 하나의 GPU를 잘게 쪼개서 여러 곳에 효율적으로 사용하는게 목표였다. 마치 고스펙 서버를 사서 가상화 VM을 올리는 행위를 하고싶다는 말로 이해하면 되겠다.
1. AI 워크로드에 대한 컨테이너 사용
컨테이너 기술은 주로 두 가지 핵심 Linux 커널 기능에 의존한다.
- Cgroups (Control Groups): 프로세스 그룹의 리소스 사용(CPU, 메모리, 디스크 I/O, 네트워크 등)을 제한하는 메커니즘
- Namespaces: 프로세스가 시스템의 특정 리소스만 볼 수 있도록 논리적으로 격리하는 기능 Linux는 여러 유형의 네임스페이스(PID, 네트워크, 마운트, UTS, IPC, 사용자 등)를 제공
즉 간단히 말해 Cgroups을 통해서 리소스를 통제하고, Namespaces를 통해서 리소스를 격리하도록 하는게 컨테이너 기술이다. 당연히 다양한 모델을 컨테이너로 올리려는 시도가 있었으나 GPU의 경우 이를 격리하는 방법이 발전하지 못했다.
그러다가 최근에 MIG(Multi-Instance GPU) 기술을 통해서 점점 생기기 시작했다. GPU 기법에도 다양한 기술이 있는데 MIG 기술은 하나의 물리 GPU를 여러 논리 GPU로 쪼개서 사용하는 기술이다. 이를 통해서 컨테이너 환경에서도 보다 잘 적용할 수 있게 되었다.
https://brunch.co.kr/@f38b64b143b343c/19
GPU를 이렇게 쓴다고? MIG 모드와 분할 사용!
구매도 유지도 비싼 GPU, 더 효율적으로 쓰는 방법이 있다! | 안녕하세요, 에디터 SA입니다. AI 개발과 학습에 있어 꼭 필요한 것이 있습니다. 바로 ‘GPU’인데요. 이 GPU에 대해서, 소신 발언을 해볼
brunch.co.kr
https://everenew.tistory.com/491
MIG와 vGPU의 차이 (GPU 가상화)
몇 년 전 대학교 연구실에서 모델 학습에 일반 컴퓨터 GPU와 A100을 써본 경험이 있다.모델 학습에 파라미터를 조금씩 바꾸어 수십 번을 테스트해 보곤 했는데, 학교의 GPU 클러스터의 자원이 모자
everenew.tistory.com
1.1컨테이너 환경에서 GPU 사용의 변천사
초기단계(2016-2018)
GPU 장치 파일을 컨테이너에 직접 마운트하고 필요한 라이브러리를 볼륨으로 공유함
docker run --device=/dev/nvidia0:/dev/nvidia0 \
--device=/dev/nvidiactl:/dev/nvidiactl \
-v /usr/local/cuda:/usr/local/cuda \
tensorflow/tensorflow:latest-gpu
따라서 모든 파일을 수동으로 지정하기 때문에 휴먼에러 발생가능성, 호스트와 컨테이너 간 라이브러리 버전 충돌 가능성, 각 컨테이너간 GPU 공유 메커니즘의 부재 등 다양한 문제가 발생
NVIDIA Container Runtime 등장 (2018-2020)
NVIDIA는 이런 단점을 보완하기 위해 Container Runtime을 개발하여 공유함. 따라서 앞서 옵션값으로 설정했던 대부분의 디바이스 정보나 라이브러리 등을 OCI로 해결함.
# Docker 19.03 이전 버전 사용
docker run --runtime=nvidia nvidia/cuda:11.0-base nvidia-smi
# Docker 19.03 이후부터는 더 간단하게 --gpus 플래그를 사용
docker run --gpus '"device=0,1"' nvidia/cuda:11.0-base nvidia-smi
이 방식을 통해서 GPU를 자동으로 검출하고, 호스트-컨테이너 간 드라이버 호환성을 자동으로 관리해주면서 효율을 높임.
Kubernetes 장치 플러그인 등장 (2020-현재)
kubernetes 오픈소스에 Deivce Plugin을 만들었음. https://github.com/kubernetes/design-proposals-archive/blob/main/resource-management/device-plugin.md
NVIDIA 디바이스 플러그인 도 이에 자체 디바이스 플러그인을 제작했고, pod 스펙에서 선언적으로 GPU 리소스를 요청할 수 있음.
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: nvidia/cuda:11.0-base
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 2 # 2개의 GPU 요청
따라서 gpu를 선언적으로 관리할 수 있으며, 클러스터 수준에서 GPU 리소스 스케줄링이 가능하고, GPU 할당 격리를 자동화할 수 있게됨.
실습 1. GPU Time-slicing on Amazon EKS
해당 실습은 먼저 EKS 클러스터를 생성하고 GPU 노드그룹하여 time-slicing 기법을 활용하는게 목적이다.
GPU sharing on Amazon EKS with NVIDIA time-slicing and accelerated EC2 instances | Amazon Web Services
In today’s fast-paced technological landscape, the demand for accelerated computing is skyrocketing, particularly in areas like artificial intelligence (AI) and machine learning (ML). One of the primary challenges the enterprises face is the efficient ut
aws.amazon.com
이 실습은 eksdemo 명령어를 사용한다.
eksdemo는 eks 클러스터를 데모용으로 좀 더 쉽게 사용하기 위해 사용한다.
brew tap aws/tap
brew install eksdemo
eksdemo 명령어를 통해서 gpusharing-demo라는 이름의 eks cluster를 만들고 t3.large를 노드로 둔다.
eksdemo create cluster gpusharing-demo -i t3.large -N 2 --region ap-northeast-2 --dry-run
dry run이기 때문에 해당 명령어를 실행할 경우 생성되는 리소스 정보를 미리 확인할 수 있다.

eks 클러스터 생성
eksdemo create cluster gpusharing-demo -i t3.large -N 2 --region ap-northeast-2
설치가 모두완료되면 다음과 같이 kube-config까지 다운받아 준다. 따라서 다음 명령어로 노드를 확인해보자.
kubectl get nodes
GPU 노드 그룹 추가
GPU 노드그룹을 추가하기 앞서 인스턴스 유형에서 어떤 엑셀러레이터를 지원하는지 확인할 수 있다. 유명한 H200 뿐아니라 거의 대부분의 GPU 엑셀러레이터를 지원하는 인스턴스 유형이 존재하고 있다. 다만 quotas를 획득하는데 어려움이 있기 때문에 전략적으로 잘 사용해야한다.
https://docs.aws.amazon.com/ko_kr/ec2/latest/instancetypes/ac.html#ac_hardware

이번 실습에서 gpu 노드는 g5.8xlarge를 사용하므로 quotas 신청을 진행해야한다.
eksdemo create nodegroup gpu -i g5.8xlarge -N 1 -c gpusharing-demo --dry-run
gpu 추가시 taints도 같이 잡아주는 모습이다.

다음 명령어로 GPU 노드 그룹을 생성한다.
eksdemo create nodegroup gpu -i g5.8xlarge -N 1 -c gpusharing-demo
AZ 별로 해당 GPU 노드가 불가능한 경우도 있기 때문에 일반적으로 자동으로 AZ를 잡아주지만 테라폼 등 본인이 특정 AZ를 지정해야하는 상황이라면 반드시 해당 리전에 사용가능한지를 확인해봐야한다.
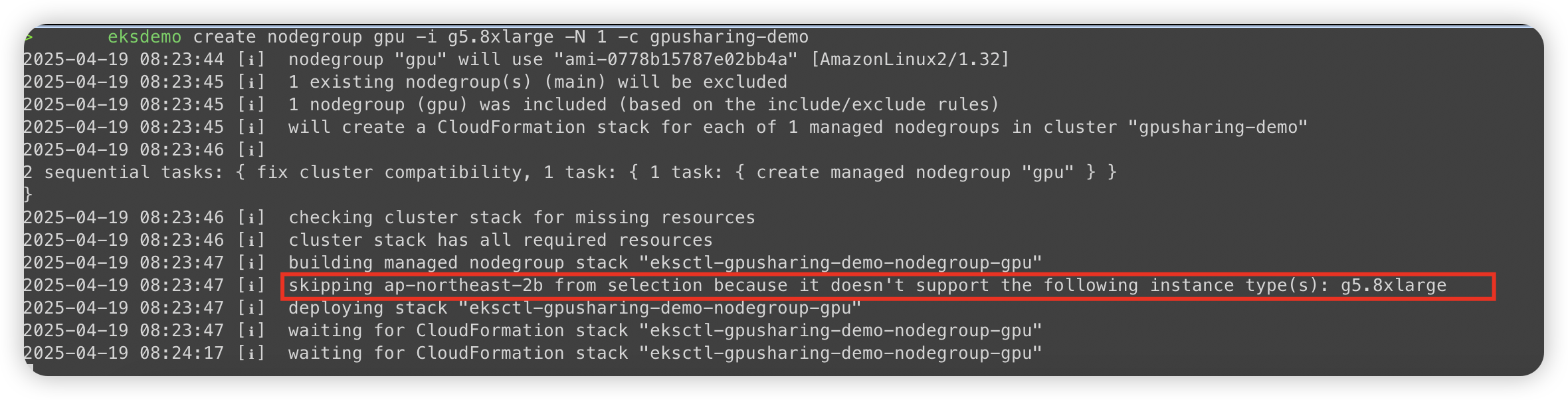
다음 명령어를 통해서 어떤 az가 가능한지 확인해 볼 수 있다. 예를 들어 서울리전(ap-northeast-2)에서 g5.8xlarge가 가능한 AZ를 확인하는 명령어이다.
aws ec2 describe-instance-type-offerings --location-type availability-zone --filters "Name=instance-type,Values=g5.8xlarge" --region ap-northeast-2 --query "InstanceTypeOfferings[*].Location" --output table
자 이제 모든 환경 설정을 마쳤으니 time-slicing 여부를 통해 비교분석 해보자.
GPU Time-slicing on Amazon EKS - Time Slicing 안했을 때
(quotas 부족으로 g5.xlarge로 실습하게 되었음)
GPU 서버가 잘 생성되었는지 get node 명령어로 확인해봅시다.
kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
annotation 기반으로 작동하므로 g5 - GPU 노드 에 "eks-node=gpu"라는 label을 지정하고 잘 붙었는지 확인해봅니다.
kubectl label node i-0685d68356125e38c.ap-northeast-2.compute.internal eks-node=gpu
# 라벨검색
kubectl get node --show-labels | grep eks-node
# nvdp-values.yaml 파일 다운로드 $
curl -O https://raw.githubusercontent.com/sanjeevrg89/eks-gpu-sharing-demo/refs/heads/main/nvdp-values.yaml
helm을 사용해 nvidia-device-plugin을 설치한다.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace kube-system \
-f nvdp-values.yaml \
--version 0.14.0
nvidia 플러그인은 기본적으로 daemonset으로 구동되기 때문에 daemonset을 확인해보면 생성된 것을 확인할 수 있다.
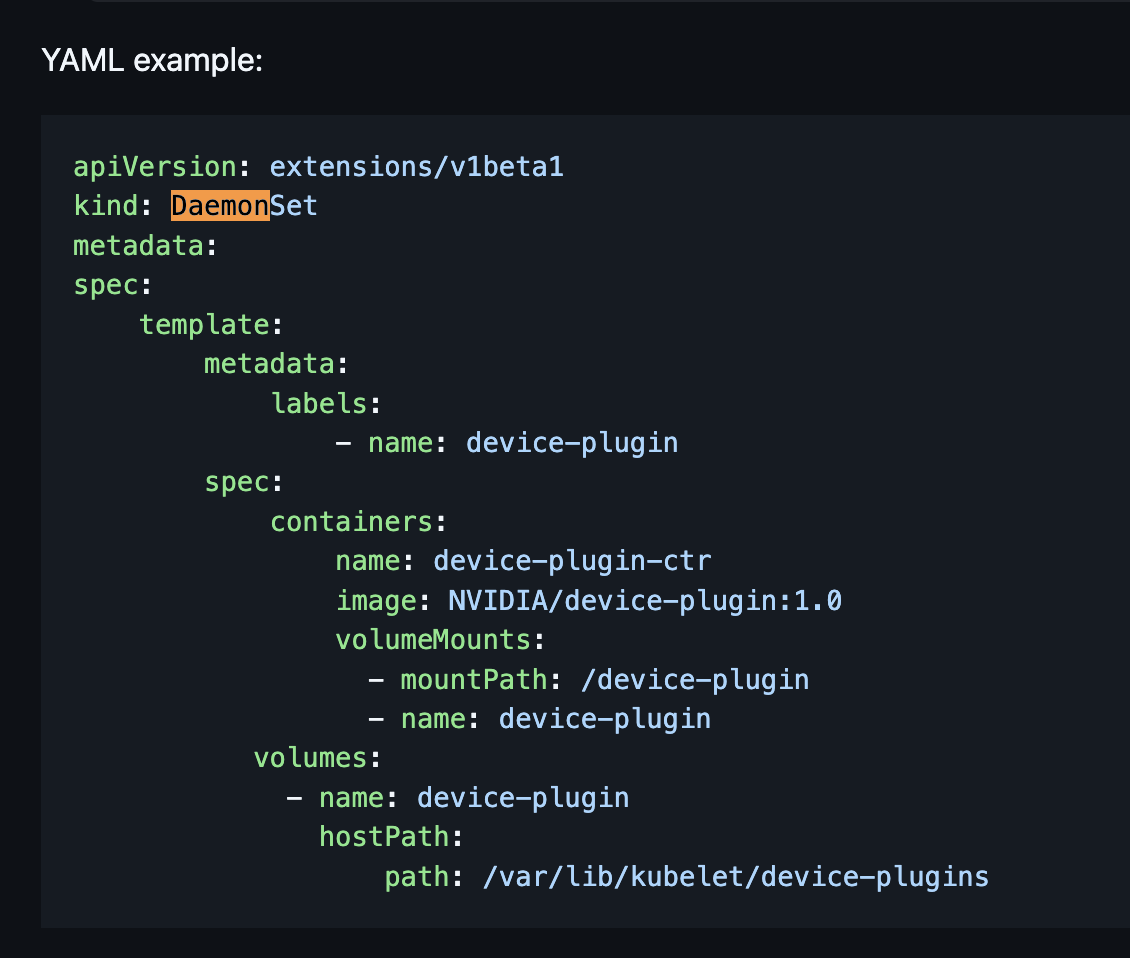
kubectl get daemonset -n kube-system | grep nvidia

현재 time-slicing을 안했기 때문에 GPU값이 1개임을 확인할 수 있다.
kubectl get nodes -o json | jq -r '.items[] | select(.status.capacity."nvidia.com/gpu" != null) | {name: .metadata.name, capacity: .status.capacity}'
GPU 모델 배포
gpu 모델을 배포해봅시다. 중요한 것은 아니지만 모델은 public.ecr.aws/r5m2h0c9/cifar10_cnn:v2를 사용했습니다.
# 네임스페이스생성
kubectl create namespace gpu-demo
# 모델 배포
cat << EOF > cifar10-train-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tensorflow-cifar10-deployment
namespace: gpu-demo
labels:
app: tensorflow-cifar10
spec:
replicas: 3
selector:
matchLabels:
app: tensorflow-cifar10
template:
metadata:
labels:
app: tensorflow-cifar10
spec:
containers:
- name: tensorflow-cifar10
image: public.ecr.aws/r5m2h0c9/cifar10_cnn:v2
resources:
limits:
nvidia.com/gpu: 1
EOF
# 실행
kubectl apply -f cifar10-train-deploy.yaml
# 모니터링
watch -d 'kubectl get pods -n gpu-demo'
pod를 살펴보면 gpu 리소스가 부족하기 때문에 생성이 불가능한 것을 볼 수 있다.
GPU스펙이 아무리 남아도 리소스가 1개이기 때문이다.
kubectl get pods -n gpu-demo
kubectl describe pod tensorflow-cifar10-deployment-7c6f89c8d6-dptqn -n gpu-demo

자 그럼 이제 time-slicing을 사용해보도록 하겠습니다.
configmap을 통해서 timeslicing을 10개 replicas로 변경해보겠습니다.
cat << EOF > nvidia-device-plugin.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nvidia-device-plugin
namespace: kube-system
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 10
EOF
# 실행
kubectl apply -f nvidia-device-plugin.yaml

새로운 configmap 기반으로 다시 plugin을 helm으로 설치합니다.
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace kube-system \
-f nvdp-values.yaml \
--version 0.14.0 \
--set config.name=nvidia-device-plugin \
--force
GPU 값이 10개로 늘어난 것을 바로 확인할 수 있습니다.

아까 pending이던 pod들이 모두 Running으로 실행되는 것을 확인할 수 있습니다.

근데 가끔 error 나는 pod가 있다면 리소스 부족으로 다음과 같이 out of memory 이슈가 있는 것도 있었다.

참고로 pod에 들어가서 nvidia-smi 명령어를 사용하면 gpu 사용에 대해서 확인도 가능하다.
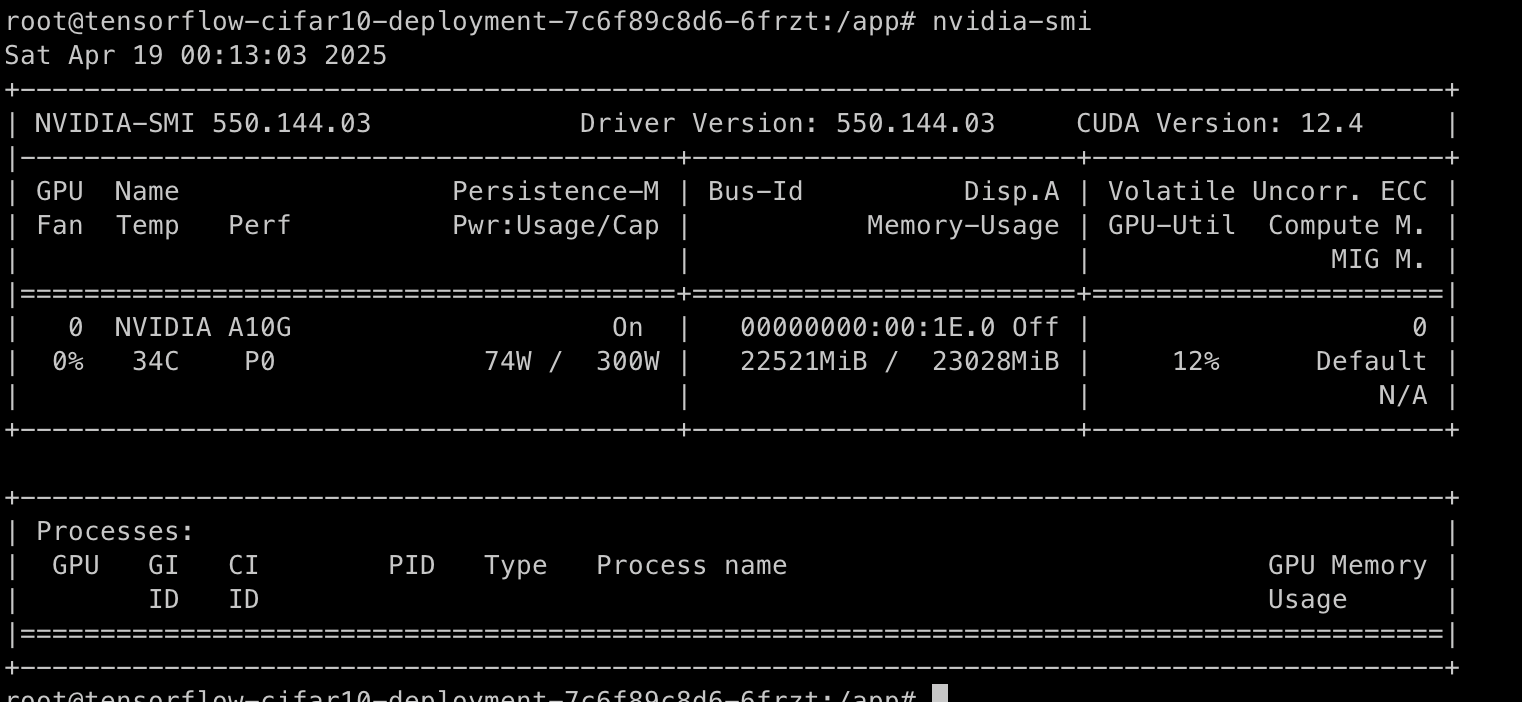
이번 실습과 내용을 통해서 EKS 환경 내에서 컨테이너로 모델을 돌리는 실습을 확인해보았다.
time-slicing 기법을 통해서 마치 VM을 여러대 띄우듯 gpu를 나눠서 사용할 수 있다는 것을 확인할 수 있었다.