이 글은 가시다님과 함께하는 AEWS 3기의 내용을 정리한 것입니다
EKS 로깅
EKS는 어떻게 로그를 남길까요? AWS 서비스이기 때문에 AWS CloudWatch에서 확인이 가능합니다.
콘솔로 설정할 경우 다음과 같습니다.
우리는 CLI로 알아보면 다음과 같이 명령어로 할 수 있습니다.
aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'결과값을 확인하면 다음과 같이 로깅에 api, audit, authenticator, scheduler 이런식으로 확인할 수 있었습니다.

로깅을 시작하면 cloudwatch에서 다음과같이 기록됩니다.
/aws/eks/<cluster-name>/cluster
로그스트림이 다음과 같이 보이는 걸 확인할 수 있습니다.

로그를 만약 aws cli를 통해서 직접 터미널에서 찍고싶으면 다음과 같이할 수 있는데요. 너무 편리합니다.
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
가끔 엑세스키가 노출되길래 가렸습니다.. 주의

만약 로그를 잠시 비활성화하거나 로그 그룹을 삭제하고 싶으면 명령어로 손쉽게 할 수 있습니다.
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region ap-northeast-2 --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
CloudWatch / Fluent Bit을 활용한 로깅
Fluentbit은 EKS 로깅에 필수적이고, fortigate 로깅에서도 많이 쓰이는 것중 하나입니다.
회사에서 syslog를 보낼때도 이걸로 사용했거든요. 사용법만 알아두면 오히려 쉽고 유용하게 쓸 수 있는 기능입니다.
AWS cloudwatch는 AWS에서 제공하는 로그 시스템으로 매우 유명한 서비스죠.

Pod (컨테이너) 로그
일단 먼저 컨테이너 로그는 어디에 저장될까요!!
우리가 docker를 사용하면 /var/lib/docker아래 모든 로그가 저장되는 것을 확인할 수 있습니다.
EKS의 경우 /var/log/containers에서 저장되는 것을 확인할 수 있습니다.
sudo tree /var/log/containers
사진에 보면 각각 로그가 심볼릭링크를 통해서 /var/log/pods에서 pod의 로그로 관리되는것을 확인할 수 있죠.
호스트 로그
자 그럼 호스트 로그는 어디서 저장될까요?
바로 /var/log 밑에 전부 저장됩니다.
sudo tree /var/log/ -L 1
이 중에 dataplane 로그를 보려면 journal로 들어가면됩니다.
sudo tree /var/log/journal -L 1
읽어보려고 시도했지만 암호화되어있어 실패했습니다.

CloudWatch를 통한 모니터링
Control plane은 우리가 관리할 수 없기 때문에 설정을 통해서 cloudwatch에 로그를 쌓도록 했습니다.
하지만 Data plane의 경우는 우리가 직접 설정할 수 있죠.
먼저 IRSA를 만들어야합니다.
CloudWatchAgentServerPolicy라는 정책을 붙이는 myeks-cloudwatch-agent-role과 함께 IRSA를 만듭니다.
eksctl create iamserviceaccount \
--name cloudwatch-agent \
--namespace amazon-cloudwatch --cluster $CLUSTER_NAME \
--role-name $CLUSTER_NAME-cloudwatch-agent-role \
--attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy \
--role-only \
--approve
EKS addon을 배포합니다.
aws eks create-addon --addon-name amazon-cloudwatch-observability --cluster-name myeks --service-account-role-arn arn:aws:iam::<IAM User Account ID직접 입력>:role/myeks-cloudwatch-agent-role콘솔내에서 저렇게도 확인이 가능합니다.


cloudwatch와 관련된 CRD를 조회해보면 다음과 같이 깔린것을 확인할 수 있습니다.
kubectl get crd | grep -i cloudwatch
이렇게 파드 로그를 확인해보면 엄청 많이 올라오는 것을 확인할 수 있습니다.
kubectl -n amazon-cloudwatch logs -l app.kubernetes.io/component=amazon-cloudwatch-agent -f
이렇게 flunet-bit 정보도 볼 수 있습니다. flunetbit은 configmap을 통해서 설정값을 정의합니다.
kubectl describe cm fluent-bit-config -n amazon-cloudwatch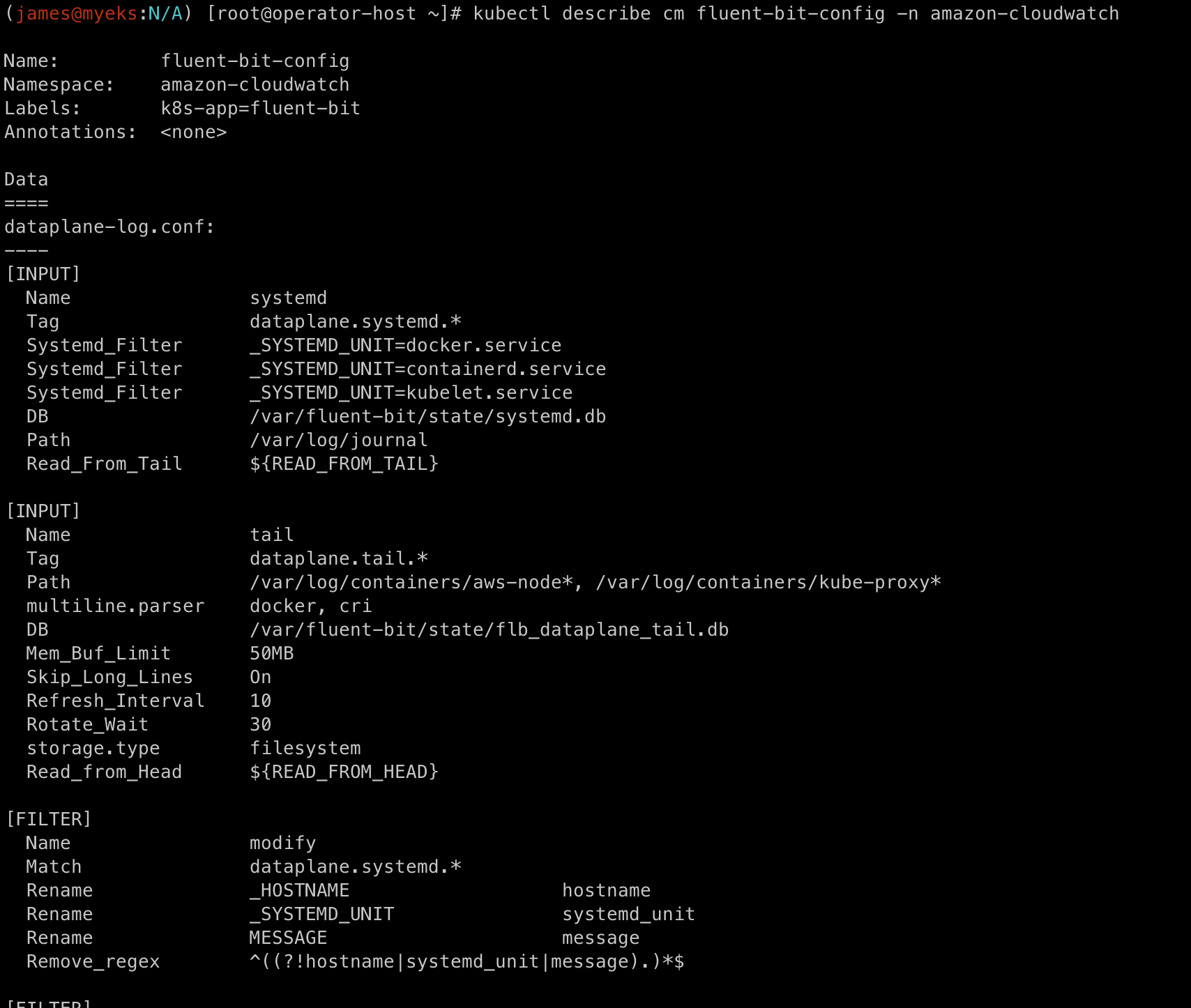
그리고 이번 스터디에 Container Insight라는 것도 처음 보게 되었는데 정말 간편하게 제공하는 기능이 많다고 생각됩니다.


Metrics-server
메트릭서버는 HPA 설정등에 반드시 필요하기 때문에 설치해야합니다. 기본적으로 쿠버네티스 파드들의 리소스를 체크하는데 사용합니다.
기존에는 helm으로 설치했는데 요즘은 EKS에서 addon으로 배포하고 있어서 매우 편합니다.
일단 기본적으로 metrics-server는 cAdvisor라는 데몬을 이용해서 메트릭을 수집합니다.

기존에 이렇게 배포된 게 있습니다. 기본적으로 15초 간격으로 메트릭을 가져오고 있습니다.

실제로 값은 top 등으로 확인이 가능한데, k9s 등을 활용하시면 바로 그냥 확인도 가능합니다.
kubectl top node
KWatch
다양한 툴들이 많은데 kwatch를 활용해서 모니터링을 할 수도 있습니다.
설치
namespace와 관련 configmap을 설정하고 배포합니다.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'SLACK URL'
title: james-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
바로 이렇게 알림이 오는 것을 확인할 수 있습니다.

장애상황 발생
잘못된 파드를 배포해보겠습니다.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-19
spec:
containers:
- name: nginx-pod
image: nginx:1.19.19 # 존재하지 않는 이미지 버전
EOF
잘못된 파드가 배포되자마자 이렇게 알림이 오는 걸 확인할 수 있습니다.
Log/Event 정보가 같이 오기 때문에 확인이 가능합니다.

PVC 알림 발생하기
지금 안됩니다. github에서 마침 읽다가 issue에서도 발견되었네요.
그래도 혹시 fix될 수 있으니 예시만 넣어놓겠습니다.

먼저 PVC와 Pod를 배포합니다. 5GiB로 설정했습니다.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-pod
namespace: default
spec:
containers:
- name: test-container
image: busybox
command: ["/bin/sh", "-c", "sleep 3600"]
volumeMounts:
- mountPath: "/data"
name: test-storage
volumes:
- name: test-storage
persistentVolumeClaim:
claimName: test-pvc
EOF
pvc가 준비되는 동안 기다립니다.
kubectl wait --for=condition=Ready pod/test-pod --timeout=60s
pod에 접속해 70%까지 더미데이터를 채웁니다.
kubectl exec test-pod -- sh -c "dd if=/dev/zero of=/data/dummyfile bs=1M count=3500"
사용량을 확인해봅니다.
kubectl exec test-pod -- sh -c "df -h /data"
알림 발생은 로그를 통해서 바로 확인가능합니다.
kubectl logs -l app=kwatch -n kwatch --tail=50
아쉽게도 지금은 전송이 안되지만 로직 개선이 될때 다시 시도해보면 좋을것 같아 기록해둡니다.